
Creating 33,000 coupon codes in Stripe using AWS Serverless and AWS CDK
This was a fun little project spun up using AWS Serverless tech to help a team member out creating a shed ton of coupon codes in Stripe. All put together using AWS CDK, a nice use-case to connect a handful of AWS services together.

No one wants to do anything by hand - so this week I helped a member of the team with an interesting challenge. They needed to create 33,000 unique coupon codes in our Stripe account for an upcoming marketing campaign.
Being the AWS fanboy I am and an AWS Cloud Development Kit (CDK) lover, I thought this was perfect for a mini project to be spun up to tackle the job.
A bit of background
To set the scene, a lot of the prep work had already been done. I had been given a CSV file (example below) of what we wanted each code to be and the parent coupon we wanted each promotion code in Stripe to sit under.
coupon,max_redemptions,code
EXAMPLECOUPON,1,SUPERMAN
EXAMPLECOUPON,1,SPIDERMAN
EXAMPLECOUPON,1,TOM
EXAMPLECOUPON,1,JERRY
+ 32,996 more
Before turning to an AWS solution, we had looked at if we could use our Zapier account to do the heavy lifting, turns out this was going to blow through our budget for the month on just this transaction so we ruled that out. Here comes AWS and CDK to the recuse.
Proper planning prevents...
My plan was to use AWS serverless technology to whiz through these 33,000 promotional codes and create them in our Stripe account. First of all I needed a way to process each of these codes. Second of all I needed to be mindful of the Stripe rate limit. For our account we are limited to 100 requests per second of writing. So even at that maths if I could get it bang on the rate limit, it would take 5 and a half solid mins of processing to complete.
This is not taking into account all the other API requests our platform would be making at the time as customers move through our systems. So I knew I needed to leave some headroom as it was going to take some time.
Like the start of every good challenge, I dived into Miro and whipped up a rough sketch of what I was thinking. Create an S3 bucket to house the CSV file, then I would trigger off a Lambda function that would pull from the bucket and loop over the CSV to put a message onto a queue for each code we needed to create. Then using that queue I'd have another Lambda set to poll from the queue and create the promo code in Stripe.
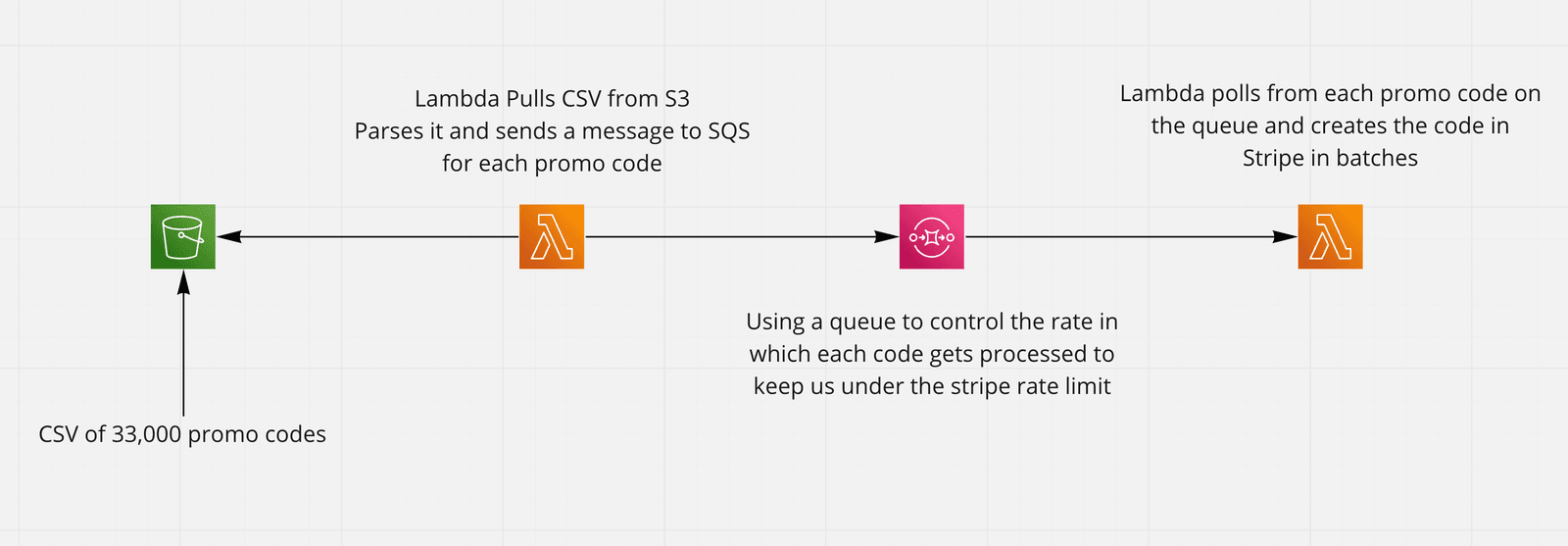
Where the magic happens
Part 1: S3 Buckets
Time to get CDK rocking so let's dive in. I created a blank CDK project using the TypeScript template so we were good to go. First I needed the S3 bucket to house this CSV file...
import * as S3 from 'aws-cdk-lib/aws-s3';
const promoCodesBucket = new S3.Bucket(this, 'PromoCodesBucket', {
autoDeleteObjects: true,
removalPolicy: RemovalPolicy.DESTROY,
});
The real nice thing about CDK is a lot of the level 3 constructs have handy props that can
perform actions for you. Here I am setting the removalPolicy and autoDeleteObjects
so that when I destroy this stack after testing it will also remove the bucket for me.
By default the bucket will be left there in my account after the stack is deleted.
Next is a super handy feature I only learnt recently, to get the CSV file into the bucket.
I thought I would have to upload it manually but nope, in CDK it has a built in BucketDeployment
construct that will let you map a local folder within your repository to an S3 bucket.
Plus keeping it in sync when you make any changes to the files.
import * as S3Deployment from 'aws-cdk-lib/aws-s3-deployment';
new S3Deployment.BucketDeployment(this, 'PromoCodesBucketDeployment', {
sources: [S3Deployment.Source.asset('src/buckets/promo-codes')],
destinationBucket: promoCodesBucket,
exclude: ['*.DS_Store'],
});
So I created a folder locally that I wanted to be my bucket contents and pointed my deployment at that. Behind the scenes I believe this is creating another Lambda function that take cares of the deployment for you. One thing to note is for cleanliness I added an exclude array as it was picking up a DS_Store file on my Mac in this folder.
Part 2: A Lambda to pull from S3 & Publish to Queue
Next I needed a Lambda function that was going to pull the file from this bucket, parse it
and then publish a message to a queue for each promo code. To do this I used a NodeJsFunction
Lambda in CDK which are super nice. They allow you to use TypeScript out the box and will
bundle/compile on the deployment for you.
import { Duration } from 'aws-cdk-lib';
import { Runtime } from 'aws-cdk-lib/aws-lambda';
import { RetentionDays } from 'aws-cdk-lib/aws-logs';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
const processFromBucketLambda = new NodejsFunction(this,'ProcessFromBucketLambda', {
runtime: Runtime.NODEJS_14_X,
entry: 'src/functions/process-from-bucket/index.ts',
handler: 'default',
bundling: { minify: true },
memorySize: 768,
timeout: Duration.minutes(5),
logRetention: RetentionDays.TWO_WEEKS,
environment: {
PROMO_BUCKET_NAME: promoCodesBucket.bucketName,
PROCESSING_QUEUE_URL: promoCodesQueue.queueUrl,
},
});
promoCodesBucket.grantRead(processFromBucketLambda);
A couple of things to watch out for here. By default these NodejsFunction Lambdas don't set any minification for you so it's probably a good thing to turn that on. Also I increased the timeout and memory size to give us a bit more oomph to churn through the large CSV.
Possibly my favourite feature about CDK is the built in permissions out the box promoCodesBucket grantRead(processFromBucketLambda); - saves proper admin having to config IAM roles or polices for this transaction to happen.
Part 3: A queue to connect the dots
Short and sweet this part. A one liner to create a new queue. All the defaults out the box were fine for this task since the queue is only going to be short lived. I should have probably connected a Dead Letter Queue onto this if for some reason we failed to process them.
import * as Sqs from 'aws-cdk-lib/aws-sqs';
const promoCodesQueue = new Sqs.Queue(this, 'PromoCodesQueue', {});
One of the main reasons of using this queue was to control the rate in which these coupons were created. I needed to keep this under the Stripe rate limit as previously mentioned but this also allowed me to batch up the creation of these codes easily plus have multiple created at one time asynchronously.
Part 4: A Lambda to process messages from the queue
Now for the main event. I used a second Lambda function to pick up these messages from the queue and create the code in Stripe. This is pretty straight forward using the the Stripe npm package.
import { Duration } from 'aws-cdk-lib';
import { Runtime } from 'aws-cdk-lib/aws-lambda';
import { RetentionDays } from 'aws-cdk-lib/aws-logs';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import { SqsEventSource } from 'aws-cdk-lib/aws-lambda-event-sources';
const processFromQueueLambda = new NodejsFunction(this, 'ProcessFromQueueLambda', {
runtime: Runtime.NODEJS_14_X,
entry: 'src/functions/process-from-queue/index.ts',
handler: 'default',
bundling: { minify: true },
memorySize: 768,
timeout: Duration.minutes(5),
logRetention: RetentionDays.TWO_WEEKS,
reservedConcurrentExecutions: 5,
});
processFromQueueLambda.addEventSource(
new SqsEventSource(promoCodesQueue, {
batchSize: 10,
}),
);
The setup here is pretty similar to the previous Lambda, except I am using the
reservedConcurrentExecutions prop to control the maximum number of current
invocations this Lambda runs at.
Also I need to connect this Lambda up to the queue using the SqsEventSource with a
batchSize of 10. Coupling this with the reservedConcurrentExecutions should mean
that this setup is processing 50 coupon codes at once.
Bonus Part 5: Secret Manager
Little bonus section here. I did also use AWS Secrets Manager to pull our production Stripe API key from. In order to do this I needed to give the processing from queue Lambda function permission.
import { Policy, PolicyStatement } from 'aws-cdk-lib/aws-iam';
const getParametersByPathPolicy = new PolicyStatement({
actions: ['secretsmanager:GetSecretValue'],
resources: ['arn:aws:secretsmanager:*'],
});
processFromQueueLambda.role?.attachInlinePolicy(
new Policy(this, 'GetParametersByPathPolicy', {
statements: [getParametersByPathPolicy],
}),
);
The Full Picture
If you completely skipped over that as it made no sense then apologies, here is the full stack all together ready to go.
import { Duration, RemovalPolicy, Stack } from 'aws-cdk-lib';
import { Runtime } from 'aws-cdk-lib/aws-lambda';
import { NodejsFunction } from 'aws-cdk-lib/aws-lambda-nodejs';
import { RetentionDays } from 'aws-cdk-lib/aws-logs';
import { Construct } from 'constructs';
import { paramCase } from 'param-case';
import * as S3 from 'aws-cdk-lib/aws-s3';
import * as S3Deployment from 'aws-cdk-lib/aws-s3-deployment';
import * as Sqs from 'aws-cdk-lib/aws-sqs';
import { SqsEventSource } from 'aws-cdk-lib/aws-lambda-event-sources';
import { Policy, PolicyStatement } from 'aws-cdk-lib/aws-iam';
export interface StripePromoStackProps {
description?: string;
deleteDataOnDestroy?: boolean;
}
export class StripePromoStack extends Stack {
constructor(scope: Construct, id: string, props?: StripePromoStackProps) {
const physicalId = paramCase(id);
super(scope, id, {
stackName: physicalId,
description: props?.description,
});
const promoCodesBucket = new S3.Bucket(this, 'PromoCodesBucket', {
autoDeleteObjects: true,
removalPolicy: RemovalPolicy.DESTROY,
});
new S3Deployment.BucketDeployment(this, 'PromoCodesBucketDeployment', {
sources: [S3Deployment.Source.asset('src/buckets/promo-codes')],
destinationBucket: promoCodesBucket,
exclude: ['*.DS_Store'],
});
const promoCodesQueue = new Sqs.Queue(this, 'PromoCodesQueue', {});
const processFromBucketLambda = new NodejsFunction(this, 'ProcessFromBucketLambda', {
runtime: Runtime.NODEJS_14_X,
entry: 'src/functions/process-from-bucket/index.ts',
handler: 'default',
bundling: { minify: true },
memorySize: 768,
timeout: Duration.minutes(5),
logRetention: RetentionDays.TWO_WEEKS,
environment: {
PROMO_BUCKET_NAME: promoCodesBucket.bucketName,
PROCESSING_QUEUE_URL: promoCodesQueue.queueUrl,
},
});
promoCodesBucket.grantRead(processFromBucketLambda);
promoCodesQueue.grantSendMessages(processFromBucketLambda);
const processFromQueueLambda = new NodejsFunction(this, 'ProcessFromQueueLambda', {
runtime: Runtime.NODEJS_14_X,
entry: 'src/functions/process-from-queue/index.ts',
handler: 'default',
bundling: { minify: true },
memorySize: 768,
timeout: Duration.minutes(5),
logRetention: RetentionDays.TWO_WEEKS,
environment: {
PROMO_BUCKET_NAME: promoCodesBucket.bucketName,
},
reservedConcurrentExecutions: 5,
});
const getParametersByPathPolicy = new PolicyStatement({
actions: ['secretsmanager:GetSecretValue'],
resources: ['arn:aws:secretsmanager:*'],
});
processFromQueueLambda.role?.attachInlinePolicy(
new Policy(this, 'GetParametersByPathPolicy', {
statements: [getParametersByPathPolicy],
}),
);
processFromQueueLambda.addEventSource(
new SqsEventSource(promoCodesQueue, {
batchSize: 10,
}),
);
}
}
And that's it...
Churning through 33,000 coupon codes from a single CSV file using AWS Serverless tech and CDK, job done.
We have used S3 to store our CSV, Lambda and an SQS to hold the whole operation together. Oh and a bit of secrets manager for good measure.
I have been absolutely loving CDK recently so stay tuned for more posts on different challenges and things we have been doing with it.
I would love to hear about how you would have gone about solving this problem. Would you have done it this way or is there another pattern you can think of?
Let me know on Twitter https://twitter.com/jackktomo what you think and I shall see you on the next one!
Jack